Journey through PostgreSQL

This is a summary of notes for later reference as I learn the foundations of PostgreSQL (later abbreviated as Postgres), an open-source relational database system that supports both SQL and JSON querying.
I thought it was fascinating that it started in 1986 in Berkeley’s CS department, my alma mater.
–
Background
-
supports many languages (Python, Java, C#, C/C+, Ruby, JavaScript (Node.js). Perl, Go, Tcl)
-
not just relational, but object-relational and passes ACID and is transactional as well.
- leads to support for user-defined objects and their behaviors including data types, functions, operators, domains and indexes; one example is the use of arrays of values
- makes it extremely flexible and robust. Complex data structures can be created, stored and retrieved.
- Standard RDBMS’ don’t support nested and composite structures which this does
-
supports many data-types:
-
uuid, monetary, enumerated, geometric, binary, network address, bit string, text search, xml, json, array, composite and range types
-
as well as some internal types for object identification and log location
-
PATHdata: A path consists of multiple points in a sequence and can be open (the beginning and end points are not connected) or closed (the beginning and end points are connected); widely important for storing geometric data -
CREATE TYPEcommand to create new data types as composite, enumerated, range and base-- create a new composite type called "wine" CREATE TYPE wine AS ( wine_vineyard varchar(50), wine_type varchar(50), wine_year int ); -- create a table that uses the composite type "wine" CREATE TABLE pairings ( menu_entree varchar(50), wine_pairing wine ); -- insert data into the table using the ROW expression INSERT INTO pairings VALUES ('Lobster Tail',ROW('Stag''s Leap','Chardonnay', 2012)), ('Elk Medallions',ROW('Rombauer','Cabernet Sauvignon',2012)); /* query from the table using the table column name (use parentheses followed by a period then the name of the field from the composite type) */ SELECT (wine_pairing).wine_vineyard, (wine_pairing).wine_type FROM pairings WHERE menu_entree = 'Elk Medallions';
-
-
Postgres can handle a lot of data. The current posted size limits are listed below:
Limit Value Maximum Database Size Unlimited Maximum Table Size 32 TB Maximum Row Size 1.6 TB Maximum Field Size 1 GB Maximum Rows per Table Unlimited Maximum Columns per Table 250 - 1600 depending on column types Maximum Indexes per Table Unlimited
–
Loading a Database:
Installing Postgres comes with:
psql: terminal-based front-end to connect to Postgres database serverpgAdmin: web-based front-end to ^
Operators
The majority of operators are omitted, as they can be found in my SQL notes on my blog; no need to be redudant!
-
Concotaenation operator
||:SELECT first_name || ' ' || last_name, email FROM customer; -
LENGTH(var) to determine length
-
DISTINCT ON: sorts results by var and then for each group of var, keeps first row of the returned result set:SELECT DISTINCT ON (bcolor) bcolor, fcolor FROM distinct_demo ORDER BY bcolor, fcolor;

-
LIMIT var OFFSET row_to_skip: can skip the first x rows before limiting -
FETCHwhich is basically LIMIT, but was a SQL-standard (LIMIT not compatible to some databases which follows standard SQL)the following is the syntax
OFFSET start { ROW | ROWS }
FETCH { FIRST | NEXT } [ row_count ] { ROW | ROWS } ONLY
#The start is an integer that must be zero or positive. By default, it is zero if the OFFSET clause is not specified. In case the start is greater than the number of rows in the result set, no rows are returned;
#The row_count is 1 or greater. By default, the default value of row_count is 1 if you do not specify it explicitly.
ex:
SELECT
film_id,
title
FROM
film
ORDER BY
title
OFFSET 5 ROWS
FETCH FIRST 5 ROW ONLY;
- Joins:
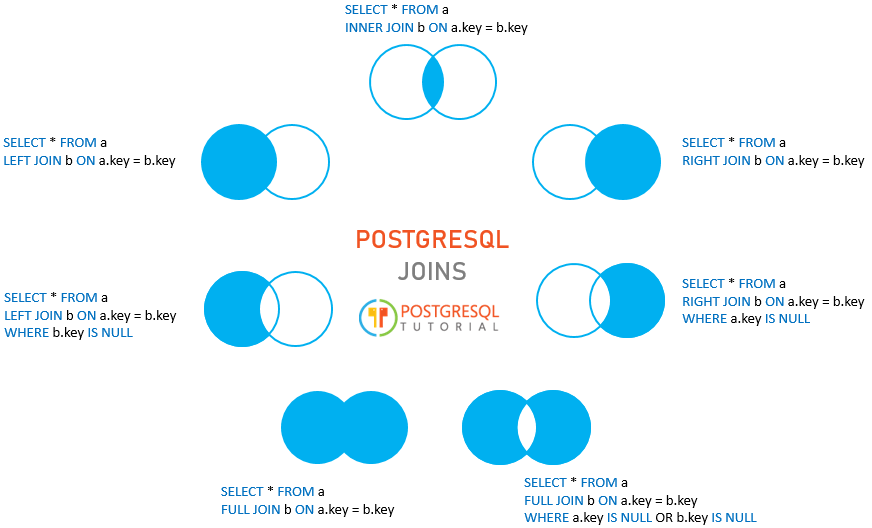
-
natural join ^ is basically an implicit join for those with same column names in joined tables
-
<>is basically != -
EXTRACTbasically extracts certain time variable from a date- example:
EXTRACT (YEAR FROM rental_date)
- example:
-
DATEconverts timestamps into dates that can be used -
The
INTERSECToperator returns any rows that are available in both result sets (appends both sets together, but checks for the intersection of two sets)UNIONappends both together without checking for same rows; removes duplicate rows (keeps throughUNION ALL)- while
EXCEPTremoves all of B and its intersection if A except B
SELECT select_list FROM A INTERSECT SELECT select_list FROM B; -
Grouping sets are basically all subsets of the data that can result when you group by a variable:
SELECT c1, c2, aggregate_function(c3) FROM table_name GROUP BY GROUPING SETS ( (c1, c2), (c1), (c2), () ); example: SELECT brand, segment, SUM (quantity) FROM sales GROUP BY GROUPING SETS ( (brand, segment), (brand), (segment), () );GROUPING()function returns bit 0 if the argument is a member of the current grouping set and 1 otherwise.CUBEsimplfiies grouping sets by including all combinations of variables as a grouping set, if there are n columns specified, then there is 2^n combinationsROLLUPgenerates grouping sets based on hiearchy, based on the order of variables selected; useful for aggregating data by year,month, and date
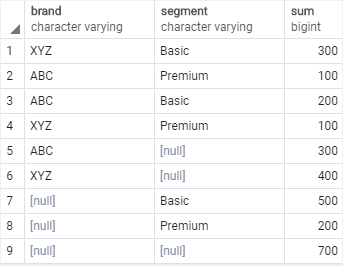
-
A subquery can be an input of the
EXISTSoperator. If the subquery returns any row, theEXISTSoperator returns true. If the subquery returns no row, the result ofEXISTSoperator is false- think of it as a boolean list that acts like a conditional to filter out rows
- If the subquery returns
NULL,EXISTSreturns true
EXISTS (SELECT 1 FROM tbl WHERE condition); -
The PostgreSQL
ANYoperator compares a value to a set of values returned by a subquery.- can also use
SOMEas a synonym - must be comparing only one column from subquery
= ANYoperator is equal toIN- but
x <> ANY(abc)is equals tox <> a OR <> b OR x <> c; not dthe same asNOT IN - the use of
ALLmeans that the conditon must be met for ALL conditions in the range, much stricter
- can also use
-
Recursive CTE’s:
WITH RECURSIVE subordinates AS ( SELECT employee_id, manager_id, full_name FROM employees WHERE employee_id = 2 UNION #recursive part to get suboordinates after #finding who manager #repeats for 3 iterations as it first starts at manager id =2, then filters out based on the different employee ids of the suboordinates SELECT e.employee_id, e.manager_id, e.full_name FROM employees e INNER JOIN subordinates s ON s.employee_id = e.manager_id ) SELECT * FROM subordinates; -
INSERT:-
INSERT INTO table_name(cols) VALUES (values)
-
can be multiple columns with multiple value lists:
-
INSERT INTO table_name (col_list) VALUES (val_list1), (val_list_n) RETURNING * | output_expression; -
returns
INSERT oid countwhich oid is a object identifier as confirmation that it was successful -
add
RETURNINGkeyword, if you want to return all of the cols added of row as an output after adding:RETURNING output_expression AS output_nameat the end of the experssion
-
omitting required columns will issue an error; will use default values for optional columns
- optional columns contain
NOT NULLwhen table is created, if doesn’t exist, then will default as NULL
-
-
UPDATE: modifies existing data-
returns
UPDATE countfor the amount of updated rows -
UPDATE table_name SET col1 = val1, col2 = val2, ... WHERE condition RETURNING *| output_expressiona as output_name -
You can also merge this syntax to join two tables that has been updated to merge:
UPDATE t1 SET t1.c1 = new_val FROM t2 WHERE t1.c2 = t2.c2
-
-
DELETE: removes one or miltiple rowsDELETE from table_name WHERE condition RETURNING (select_list | *);-
does not modify structure of the table, only removes data; use
ALTER TABLEto alter structure -
can use
DELETE FROM tableto delete all rows of a table -
can do a similar thing to update join, with the
USINGoperator:DELETE from table_name1 USING table_expression #can also be a table WHERE condition #or use subquery RETURNING returning_columns; -
USINGmay not be avaialble, thus use subquery inWHEREclause
-
-
UPSERTalso known as merge, if you insert something and it already exists, it will update the row (else insert it); update + insert-
INSERT INTO tablename(col_list) VALUES(value_list) ON CONFLICT target action; -
ON CONFLICT target actionallows this merge if there is conflict (only exists in Postgres 9 and up) -
where
targetis a col_name,ON CONSTRAINT constraint_name,WHERE predicate -
and action is
DO NOTHINGorDO UPDATE SET col_1 = val_1 ... WHERE condition- either update or do nothing if exists; refer to
EXCLUDEDwhen doing conditions on conflicted
- either update or do nothing if exists; refer to
-
-
Creating a new table, usually does the following:
-
DROP TABLE IF EXISTS tablename CREATE TABLE table_name ( var1 SERIAL PRIMARY KEY, var2 VAR_ATTR2(255) NOT NULL, etc... ); -
SERIAL= no need to supply a value, generates sequential number -
USE
CREATE TEMPORARY TABLEwhich drops it at the end of the session or a transaction -
Use
CREATE TABLE IF NOT EXISTS table_name(cols)to ensure it’s uniquea -
can use
CREATE TABLE table_name (LIKE other_tablename)to copy format of other table cols -
Some column constraints:
- NOT NULL - ensures that the values cannot be NULL
- UNIQUE - ensures values in a column are unique
- PRIMARY KEY - unique identifier for rows (only one prim key)
- CHECK - ensures that data satisfies a boolean expression
- FOREIGN KEY - can have many, refers to other tables
-
to escape
O'Riley Media', you need to use an additional signle quote (‘) to escape it:-
INSERT INTO links(url, name) VALUES('http:///www.oreiionslly.com', 'O''Reilly Media'); #notice the extra '
-
-
SELECT INTOcreates new table based on select, type of subquerySELECT select_list INTO [TEMPORARY | TEMP | UNLOGGED] [TABLE] new_table_name FROM table_name WHERE search_cond;
-
-
CREATE DOMAINcreate new data type constraints for future use, simplifies code:CREATE DOMAIN name AS DOMAIN_EXPRESSION; ex: CREATE DOMAIN contact_name AS VARCHAR NOT NULL CHECK (value !~ \'s') #contact_name cannot include spaces #then you reference this new constraint when creating a new table- use
ALTER DOMAINorDROP DOMAINto change or remove domains - view all domains in \dD
- use
-
You can also create functions using new datatypes: (\dT to view all in psql)
CREATE TYPE film_summary AS ( film_id INT, title VARCHAR, release_year SMALLINT ); CREATE OR REPLACE FUNCTION get_film_summary (f_id INT) RETURNS film_summary AS $$ SELECT film_id, title, release_year FROM film WHERE film_id = f_id ; $$ LANGUAGE SQL; SELECT * FROM get_film_summary (40); -
Coalescehelps choose the first non-null argument when trying to visualize something; ignores null arguments just in case they do not exist- Takes as much arguments; same performance as using
CASEjust in shorter form
- Takes as much arguments; same performance as using
-
EXPLAINstatement returns the execution plan which the planner generates for a given statement:-
EXPLAIN [ options] sql_statement -
options: ( https://www.postgresqltutorial.com/postgresql-explain/)
ANALYZE [ boolean ] VERBOSE [ boolean ] COSTS [ boolean ] BUFFERS [ boolean ] TIMING [ boolean ] SUMMARY [ boolean ] FORMAT { TEXT | XML | JSON | YAML } -
wrap Analyze with:
BEGIN; EXPLAIN ANALYZE sql_statement; ROLLBACK;so data isn’t affected- analyze shows runtime and execution statistics
-
Random facts
-
Order-by sorts by
ASCdefault -
specify order of NULL with
NULLS FIRSTorNULLS LASTwith ORDER BY -
The
NULLIFfunction returns a null value ifargument_1equals toargument_2, otherwise it returnsargument_1. -
CAST (expression AS target_type)or useexpression::type -
SELECT random();to get a random number between 0 and 1, can define range-
can also use
SELECT random_between(a,b)CREATE OR REPLACE FUNCTION random_between(low INT ,high INT) RETURNS INT AS $$ BEGIN RETURN floor(random()* (high-low + 1) + low); END; $$ language 'plpgsql' STRICT;
-
Transactions
-
single unit of work that consists of one or more operations
-
example: bank transfer of money to one account to another
- must ensure balance is consistent when receiving and sending X money.
-
Postgres follows ACID (atomic, consistent, isolated, and durable)
- Atomic: guarantees that transaction completes in all-or-nothing manner
- Consistent: ensures that changes to data written to database must be avalid and follow predefiend rules
- Isolation: determines how transaction integreity is visible to other transactions
- Durability; makes sure that transactions have been committed will be stored to database permanently (no matter if there’s power shortage, etc.)
- Start a transaction:
- Use
BEGIN TRANSACTIONORBEGIN WORKORBEGIN
- Use
- Commit a transaction:
COMMIT WORKorCOMMIT TRANSACTIONorCOMMIT
- Rollback a transaction:
ROLLBACK WORKorROLLBACK TRANSACTIONorROLLBACK
Importing CSV files into Postgres:
-
use
COPYstatement:COPY table(cols) #order must be same as csv file FROM DATAPATH DELIMITER ',' CSV HEADER; #HEADER ensures that there is a HEADER in csv file- will return COPY X depending how much rows were succesfully imported
- COPY usually ignores that ther eis a header unless specified
- file must be read directly by Postgres server and not the client app
-
Use
pgadmin:- refer to guide on postgresqltutorial.com
Exporting CSV files from Postgres:
-
In similar fashion, use
COPY:COPY table_name(cols) TO PATH DELIMITER ',' CSV HEADER;- don’t include HEADER if you don’t want the header of columns, and don’t specify columns if you want the whole table
-
Can also write it in
psqlusing \copy:\copy (SELECT * FROM table_name) to PATH with csv
Data Types:
-
Character:
CHAR(n)- fixed length, with space padded (when it does not fit n)VARCHAR(n)- variable-length, no space paddingTEXT- unlimited length, variablelength character string
-
Boolean/bool: supports T,F, Nulll; flexible in supporting
TRUEandFALSEvalues- use
SET DEFAULTwhen altering table orDEFAULTwhen creating a table
- use
-
Integer:
-
SMALLINT: 2-byte signed integer (-32,768 to 32,767) -
INT: 4-byte integer (-2mil to 2,147,483,647) -
SERIAL: as mentioned before, generates and opulates values in increment-
UUID: stores unique identifiers that guarantees better uniqueness thanSERIAL(used to hide senisitve data) -
to use, install
uuid-osspmodule using:CREATE EXTENSION IF NOT EXISTS "uuid-ossp"; -
then generate using
uuid_generate_v1();- there’s different functions from v1 to v4 (look at documentation)
-
-
-
Float:
FLOAT(n): floating-point whose precision is at least n bytes up to maximum of 8 bytesREALorFLOAT8: 4-byte floating-point numberNUMERIC(p,s): real number with p digits with s number after the decimal point
-
Date:
- includes date, time, timestamp, timestampz (includes timezone), interval
-
Arrays
-
Json/JsonB (stores json in binary format, faster to process slower to insert)
- can use JSON operators in WHERE clause to filter rows from json type (->)
- Postgres also provides their own functions to help process json data (https://www.postgresql.org/docs/9.5/functions-json.html)
-
Special Date types: box, line, point, lseg, polygon, inet (ip4 address), macadar (MAC address)
hstore: useCREATE EXTENSION hstore;- stores key-value pairs in a single value
- formatted as key => value pairs, and are quoted using (“”)
- example: “paperback” => “5”,
- select certain key:
SELECT attr -> 'key_name' AS simplified_key_name, similar toWHERE
Sequences: refer to https://www.postgresqltutorial.com/postgresql-sequences/
CREATE SEQUENCE [ IF NOT EXISTS ] sequence_name
[ AS { SMALLINT | INT | BIGINT } ]
[ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ]
[ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ]
[ CACHE cache ]
[ [ NO ] CYCLE ]
[ OWNED BY { table_name.column_name | NONE } ]
-
use
nextval(sequence_name)to access next value in sequence for appending new values, etc. -
to access all sequences
SELECT relname sequence_name FROM pg_class WHERE relkind = 'S'; -
Delete:
DROP SEQUENCE [ IF EXISTS ] sequence_name [, ...] [ CASCADE | RESTRICT ];
Psql commands
Connect to database psql -d database -U user -W
\dtable_name: shows structure of the table- \dD = custom domains
- \dT = custom datatypes
- \dn lists all schemas
- \df all functions in current db
- \dv all views
- \du all users and their roles
\ctable_name: connects to table; specify which user connect sby\c database username\llists all databases\gexecutes previous command\sdisplays command history; can save to filename by\s filename\?for more information on avaiable commands\hlearn more about a certain sql statement- `timing` enable query execution time on and off
\eenables you to run commands in favorite editor, then save and close it to execute- can use
\efto edit functions in editors
- can use
For more resources (that are take more digestion to learn):
- Everything was summarized from this repo.
- More Resources Here: