On Missing Values

Missing values – nan, n/a, or just empty observations – have a significant effect on conclusions that can be made from data.
They can occur systematically:
- as a nonresponse: no information is provided for one or more items or for a whole unit; private subjects like income can push people to not answer
- from attrition in longitudinal studies, where participants drop out before the experiment or test ends
- on purpose – entities choose not to, or fail to, report critical statistics, such as through governments or private entities; or because the information is not available
Or at random:
- missing completely at random (MCAR): if the events that lead to any particular data-item being missing are independent both of observable variables and of unobservable parameters of interest, and occur entirely at random – causes the dataset to be unbiased
- missing at random (MAR): missingness is not random, but where missingness can be fully accounted for by variables where there is complete information – for example, knowing that some employee forgot to input certain observations on a certain day for a study on accident (reason has to be unrelated to the variable)
- missing not at random (MNAR): neither MCAR or MAR, one example is if users fail to fill in a depression survey because of their level of depression
What are some known Techniques?
During my formal education, there was no section on the why we use certain techniques to handle missing values – especially when it is such a sensitive part in the data pipeline. In my classes, they tell you to do either one of two things:
- Impute a value based on its distribution (median if the data is skewed) or fill it with the mean.
- Drop missing values otherwise (especially when there’s only few missing points)
Generally they are both easy to do, but problems tend to arise:
- Imputing with the mean or median tends to be not as accurate to the true value that is missing, which is only true if the data is MCAR. It also reduces the variance of the imputed variable and fails to preserve the relationship between the imputed variable and other variables in the dataset.
- Dropping missing values might also create more biased subsets of the true dataset if these values are missing because of a MAR or MNAR process.
Instead, we should ask:
why are the values missing? Is there a systematic reason (like it’s from a MAR/MNAR process)?
Using different models for more accurate imputation, you can use the following:
- KNN (such as 1NN) - article describing evaluation of different NN models
- predictive-mean-matching
- MICE as described more below:
Explaining MICE:
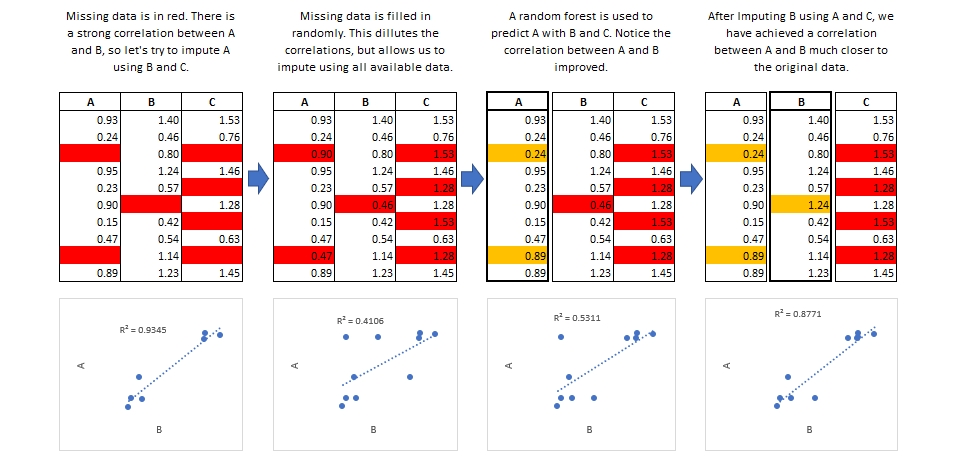
The procedure imputes missing data through an iterative series of predictive models. The model in practice is through regression.
Step 1: A simple imputation, such as imputing the mean, is performed for every missing value in the dataset. These mean imputations can be thought of as place-holders.
Step 2: The place-holder mean imputations for one variable var are set back to missing.
Step 3: The observed values from the variable var in Step 2 are regressed on the other variables in the imputation model, which may or may not consist of all of the variables in the dataset. In other words, var is the dependent variable in a regression model and all the other variables are independent variables in the regression model. These regression models operate under the same assumptions that one would make when performing linear, logistic, or Poison regression models outside of the context of imputing missing data.
Step 4: The missing values for var are then replaced with predictions (imputations) from the regression model. When var is subsequently used as an independent variable in the regression models for other variables, both the observed and these imputed values will be used.
Step 5: Steps 2–4 are then repeated for each variable that has missing data. The cycling through each of the variables constitutes one iteration or cycle. At the end of one cycle all of the missing values have been replaced with predictions from regressions that reflect the relationships observed in the data.
Step 6: Steps 2–4 are repeated for a number of cycles, with the imputations being updated at each cycle.
-
One way to evaluate different techniques is to use a known column that has no missing values. Then, you are able to drop certain observations from this column, creating “fake missing values” that will be imputed by these techniques. Then, compare the distortion, precision, and errors of these known values to test accuracy.
Although some models do not handle these types of imputation well – such as when working with timeseries which can create large assumptions that will affect the accuracy of the model. However, when working with quick predictive models like OLS, sometimes imputation with the mean might do the trick.
Having a holistic understanding on why we impute can help you decide whether to choose a complex method or not to handle missing values.
–
For more resources, I suggest looking through these two articles: